推荐系统新闻推荐正式赛
赛题以新闻APP中的新闻推荐为背景,要求选手根据用户历史浏览点击新闻文章的数据信息预测用户未来点击行为,即用户的最后一次点击的新闻文章,测试集对最后一次点击行为进行了剔除。
赛题以新闻APP中的新闻推荐为背景,要求选手根据用户历史浏览点击新闻文章的数据信息预测用户未来点击行为,即用户的最后一次点击的新闻文章,测试集对最后一次点击行为进行了剔除。
分布式光伏的装机容量也越来越高,并已开始大规模并入配电网,且开始通过各种融合终端设备接入到区域能源互联网系统,并网后数据爆发式增长。同时对分布式光伏电站的有效管理与监测。受各种环境因素的限制,光伏发电本身具有不稳定性,大规模并网会对电力系统的继电保护,电能质量,稳定性等带来很大的影响。
在这一特定背景下,对分布式光伏进行有效的监测管理显得尤为重要,对光伏发电的功率与负荷进行准确的预测不仅能辅助电网调度系统合理调整和优化发电计划,改善电网调峰能力,也能降低光伏弃光率,是产业真正实现降本增效的基础
当前面临问题:
1.如何高效的收集、处理、存储这些数据。
2.如何更好的利用这些数据,对分布式光伏进行发电功率的预测。
研究内容
1.基于Hadoop的分布式光伏大数据采集与存储研究
实现光伏数据的实时采集,处理,存储以及可视化,能够在线监测分布式光伏动态数据,
具备故障告警等功能。
2.基于DeepFM&LSTM的分布式光伏的发电功率预测研究
基于海量并网数据与相关深度学习算法,充分发挥分布式光伏电站历史数据在光伏功率
预测问题中的作用,实现对分布式光伏发电功率的准确预测。
在推荐领域 根据用户的历史活动记录预测用户下一次行为可能会选择什么项目也是一个重要 的问题,现有的推荐系统主要关注于找出用户或项目的近邻集,或者利 用隐式或显式信息 (如标签、评论、物品内容、用户属性) 来提升近邻感知能力。 然而,却少有工作利用数据当中的时序属性来参与构建推荐系统。在本篇文章中, 我将介绍数据的序列中其实包含着许多有价值的且激动人心的信息以及现代大型推荐系统是如何使用这种序列特性来提升推荐的质量的。
Bazel是Google开源的一款代码构建工具。Bazel支持多种语言并且跨平台,还支持增量编译、自动化测试和部署、具有再现性(Reproducibility)和规模化等特征。Bazel 在谷歌大规模软件开发实践能力方面起着至关重要的作用。
推荐系统中余弦相似度算法比较常用,与欧几里得不同,欧几里得比较常见,是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫”余弦相似性”。
另外:余弦距离使用两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为-1到1之间。
两个向量间的余弦值可以通过使用欧几里得点积公式求出:
比赛官网地址
给定一段时间的内存系统日志,内存故障地址数据以及故障标签数据,参赛者应提出自己的解决方案,以预测每台服务器是否会发生DRAM故障。具体来说,参赛者需要从组委会提供的数据中挖掘出和DRAM故障相关的特征,并采用合适的机器学习算法予以训练,最终得到可以预测DRAM故障的最优模型。数据处理方法和算法不限,但选手应该综合考虑算法的效果和复杂度,以构建相对高效的解决方案
本文搜集整理了从Sigmoid、ReLU到Dice等十几种常见激活函数的原理与特点,并从底层用Numpy实现和Python绘制它们。
概率论和统计中的一些相关概念:
方差
如果是在统计领域,方差就是各个样本值和全体样本值的平均数之差的平方值的平均数。如果是在概率论里,方差就是度量随机变量与其数学期望(均值)之间偏离度。
标准差
标准差是方差的平方根 ,方差虽然能很好的描述数据与均值的偏离程度,但是处理结果是不符合我们的直观思维的。举个例子:一个班级里有60个学生,平均成绩是70分,标准差是9,方差是81,假设成绩服从正态分布,那么我们通过方差不能直观的确定班级学生与均值到底具体偏离了多少分,通过标准差我们就可以直接得到学生成绩分布在[61,79]范围的概率为68%
数据类型
数据类型(统计学里也叫随机变量)有两种。也对应不同的概率分布。
离散数据根据名称很好理解,就是数据的取值是不连续的,有明确的间隔 。例如掷硬币就是一个典型的离散数据,因为抛硬币要么是正面,要么是反面,还有比如男女性别,二分类中的0/1关系等。
连续数据。连续数据正好相反,它能取任意的数值。例如时间,它能无限分割。数据十分平滑 ,还有比如年领,温度,等。是常见的变量类型。
Loss Function
损失函数 Loss Function
损失函数 Loss Function还分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,通常是针对单个训练样本而言,给定一个模型输出 y^ 和一个真实 y ,损失函数输出一个实值损失y - y^ 。用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。结构风险损失函数是指经验风险损失函数加上正则项。
Cost Function
代价函数 Cost Function 通常是针对整个训练集(或者在使用 mini-batch gradient descent 时一个 mini-batch)的总损失 。
Objective Function
目标函数 Objective Function 是一个更通用的术语,表示任意希望被优化的函数,用于机器学习领域和非机器学习领域(比如运筹优化)
即:损失函数和代价函数只是在针对样本集上有区别。
过拟合与正则化
在机器学习里,使用少量样本去拟合了所有没见过的样本, 我们叫这种现象为“过拟合”。另外,我们训练模型的数据不可避免的存在一些测量误差或者其他噪音,比如下图中10个点,我们可以找到唯一的9阶多项式 来拟合所有点;也可以使用线性模型 y = 2x 拟合。
简单来说,正则化是一种为了减小测试误差的行为(有时候会增加训练误差)。我们在构造机器学习模型时,最终目的是让模型在面对新数据的时候,可以有很好的表现。当你用比较复杂的模型比如神经网络,去拟合数据时,很容易出现过拟合现象(训练集表现很好,测试集表现较差),这会导致模型的泛化能力下降,这时候,我们就需要使用正则化,降低模型的复杂度。
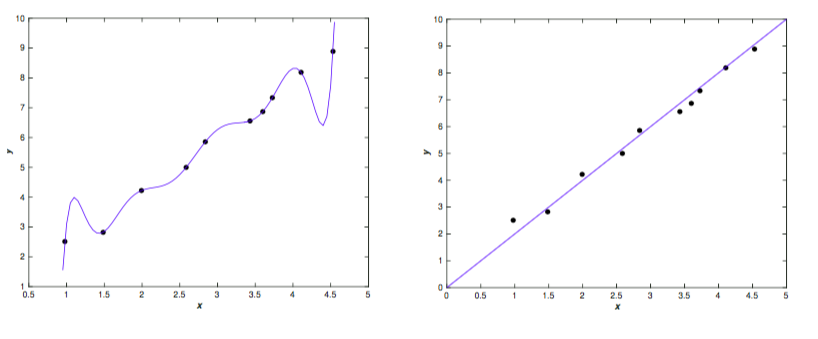
从上图可以看出,左侧的拟合结果显然的拟合到所有噪声数据了,所以我们能做的就是使用正则化技术来防止模型学到训练样本中的噪声,从而降低过拟合的可能性,让模型更加 Robust。
一句话:让更复杂模型产生好的效果的同时又不会过拟合,这就是正则化技术的作用。
模型优化方法的选择直接关系到最终模型的性能。有时候效果不好,未必是特征的问题或者模型设计的问题,很可能是优化算法的问题,而且好的优化算法还能够帮助加速训练模型。
深度学习模型的发展进程:
SGD -> SGDM ->NAG -> AdaGrad -> AdaDelta -> Adam -> Nadam

