特征选择(卡方检验与互信息)
特征选择的主要目的有两点:
- 减少特征数量提高训练速度,这点对于一些复杂模型来说尤其重要
- 减少noisefeature以提高模型在测试集上的准确性。一些噪音特征会导致模型出现错误的泛化(generalization),从而在测试集中表现较差。另外从模型复杂度的角度来看,特征越多模型的复杂度越高,也就越容易发生overfitting。
互信息(Mutual information)和卡方检验(chisquare)是两种比较常用的特征选择方法:
互信息
互信息是用来评价一个事件的出现对于另一个事件的出现所贡献的信息量,具体的计算公式为:
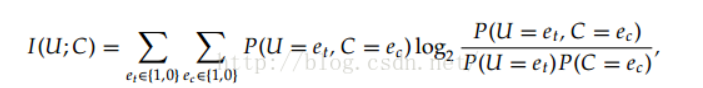
其中U、C代表两个事件,e的取值可以为0或者1,1代表出现这个事件,0代表不出现。把上述公式拆解为统计形式为:

其中N11是表示全部数据中两个事件同时出现的概率,N 表示全部事件出现的次数,而N0.则表示N01+N00
实际做单特征选择的时候,我们把某个特征是否出现和分类是否正确这两个事件放在一起计算。把得分较高的特征进行保留。
需要注意的是计算时会遇到四种情况也就是,10,11,01,00,对于其中的某一种情况,当计算得到的值是0时,代表了两者没有关联,当计算出的值是正值时,表示两者共同出现的概率比较高,当值为负时,表示两者是负相关。例如:00情况是负值是,表示两者互相排斥,出现A时,B出现的概率就比较小,这个时候往往01情况和10情况的值为正(check)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| def mutual_info(name, feature):
all_num = 0.0
pos = 0.0
neg = 0.0
null_num = 0.0
for k,v in feature.iteritems():
fea_pos = v[1]
fea_neg = v[0]
pos += fea_pos
neg += fea_neg
all_num = all_num + fea_pos + fea_neg
if k == '0':
null_num = fea_pos + fea_neg
pos_ratio = pos / all_num
neg_ratio = neg / all_num
y_ent = pos_ratio * np.log2(pos_ratio) + neg_ratio * np.log2(neg_ratio)
x_ent = 0.0
xy_ent = 0.0
for k,v in feature.iteritems():
fea_pos = v[1]
fea_neg = v[0]
v_ratio = (fea_pos + fea_neg) * 1.0 / all_num
x_ent += v_ratio * np.log2(v_ratio)
if fea_pos > 0:
v_ratio = fea_pos / all_num
xy_ent += v_ratio * np.log2(v_ratio)
if fea_neg > 0:
v_ratio = fea_neg / all_num
xy_ent += v_ratio * np.log2(v_ratio)
mi_value = xy_ent - x_ent - y_ent
print name, len(feature), null_num, mi_value
|
卡方检验
在统计学中,卡方检验用来评价是两个事件是否独立,也就是P(AB) = P(A)*P(B)
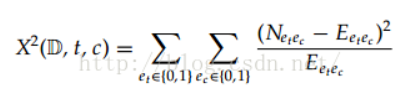
其中E代表当两者独立时期望的数量,例如E11代表两个事件独立时,共同出现的期望值。
具体的计算公式为:
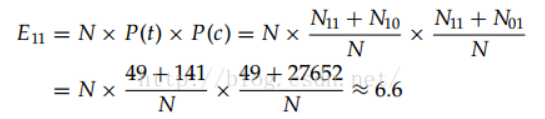
相关数据实例:

查询卡方分布在自由度为1时的显著性阈值:

284远远超过了10.83,所以二者并不独立,存在相关性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| def chi_analysis(name, feature):
all_num = 0.0
pos = 0.0
neg = 0.0
fea_count = defaultdict(float)
chi_li = []
for k,v in feature.iteritems():
chi_li.append([v[1], v[0]])
fea_pos = v[1]
fea_neg = v[0]
pos += fea_pos
neg += fea_neg
all_num = all_num + fea_pos + fea_neg
fea_count[k] = fea_pos + fea_neg
if pos == 0 or neg == 0 or len(feature) == 1:
print name, len(feature), -1
return
stat,p,dof,expected = chi2_contingency(chi_li)
prob = 0.8
critical = chi2.ppf(prob,dof)
print name, len(feature), stat, critical, p
return
pos_ratio = pos / all_num
neg_ratio = neg / all_num
chi_sum = 0.0
for k,v in feature.iteritems():
fea_ratio = fea_count[k] / all_num
pos_exp = all_num * fea_ratio * pos_ratio
neg_exp = all_num * fea_ratio * neg_ratio
chi_sum += np.square(v[1] - pos_exp) / pos_exp
chi_sum += np.square(v[0] - neg_exp) / neg_exp
print len(feature), chi_sum
|
卡方检验和互信息的区别
卡方检验对于出现次数较少的特征更容易给出高分。例如某一个特征就出现过一次在分类正确的数据中,则该特征会得到相对高的分数,而互信息则给分较低。其主要原因还是由于互信息在外部乘上了一个该类型出现的概率值,从而打压了出现较少特征的分数。
实验结果:
如果export只出现一次,且poultry为1,则在MI中的r11中log里面结果是774106/27652,但是外部的P11非常小只有1/N。在卡方检验中,E11的值为N*1/N*(27652/774106), 也就是27652/774106。
(1 -27652/774106)^2/27652/774106
没有再计算N11的比例,相对来说值会大一些。
刚开始时,卡方检验会选择一些小众特征,覆盖率不好,噪音较大,所以效果不如互信息方法,但是从100开始会选择到一些较好的特征,整体效果有所上升。

这两种方法都属于贪心方法,没有考虑到已选择特征和待选特征之间的相关性,并不能得到最优的情况。但是速度方面会非常快。
其他需要考虑的地方:是否特征选择的时候,计算概率,通过统计的方法对于一些小众特征偏差较大,通过增加先验概率的方法进行平滑可以优化结果。