余弦相似度算法
余弦相似度算法
推荐系统中余弦相似度算法比较常用,与欧几里得不同,欧几里得比较常见,是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫”余弦相似性”。
另外:余弦距离使用两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为-1到1之间。
两个向量间的余弦值可以通过使用欧几里得点积公式求出:
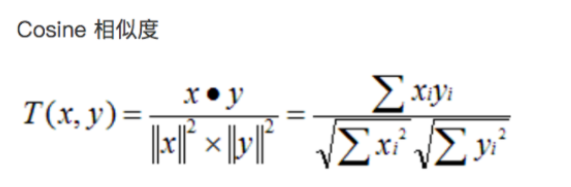
1 | import math |
1 | 0.9975694083904585 |
注意事项:
a.因为计算是基于各维度特征的绝对数值,所以欧氏度量需要保证各维度指标在相同的刻度级别,比如对身高(cm)和体重(kg)两个单位不同的指标使用欧式距离可能使结果失效。
b.欧几里得距离是数据上的直观体现,看似简单,但在处理一些受主观影响很大的评分数据时,效果则不太明显;比如,U1对Item1,Item2 分别给出了2分,4分的评价;U2 则给出了4分,8分的评分。通过分数可以大概看出,两位用户褒Item2 ,贬Item1,也许是性格问题,U1 打分更保守点,评分偏低,U2则更粗放一点,分值略高。在逻辑上,是可以给出两用户兴趣相似度很高的结论。如果此时用欧式距离来处理,得到的结果并不好。==即评价者的评价相对于平均水平偏离很大的时候欧几里德距离不能很好的揭示出真实的相似度==。
借助三维坐标系来看下欧氏距离和余弦距离的区别:
正因为余弦相似度在数值上的不敏感,会导致这样一种情况存在:
用户对内容评分,按5分制,X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得到的结果是0.98,两者极为相似。但从评分上看X似乎不喜欢2这个 内容,而Y则比较喜欢,余弦相似度对数值的不敏感导致了结果的误差,需要修正这种不合理性就出现了调整余弦相似度,即所有维度上的数值都减去一个均值,比如X和Y的评分均值都是3,那么调整后为(-2,-1)和(1,2),再用余弦相似度计算,得到-0.8,相似度为负值并且差异不小,但显然更加符合现实。
那么是否可以在(用户-商品-行为数值)矩阵的基础上使用调整余弦相似度计算呢?从算法原理分析,复杂度虽然增加了,但是应该比普通余弦夹角算法要强。
“判断两段文本的语义相似度”的事情,实验中用doc2vec做文本向量化,用余弦值衡量文本相似度。
为什么选用余弦?
如向量的维度是3,有三段文本a、b、c,文本向量化之后的结果假如如下:a=(1,0,0)、b=(0,1,0)、c=(10,0,0)。
我们知道doc2vec的每一个维度都代表一个特征,观察向量的数字,主观看来a和c说的意思应该相似,阐述的都是第一个维度上的含义,a和b语义应该不相似。那么如果用欧式距离计算相似度,a和b的相似度就比a和c的相似度高,而如果用余弦计算,则答案反之。
那么欧式距离和余弦相似度的区别是什么呢?
余弦相似度衡量的是维度间取值方向的一致性,注重维度之间的差异,不注重数值上的差异,而欧氏度量的正是数值上的差异性。
那么欧式距离和余弦相似度的应用场景是什么呢
以下场景案例是从网上摘抄的。
如某T恤从100块降到了50块(A(100,50)),某西装从1000块降到了500块(B(1000,500)),那么T恤和西装都是降价了50%,两者的价格变动趋势一致,可以用余弦相似度衡量,即两者有很高的变化趋势相似度,但是从商品价格本身的角度来说,两者相差了好几百块的差距,欧氏距离较大,即两者有较低的价格相似度。
如果要对电子商务用户做聚类,区分高价值用户和低价值用户,用消费次数和平均消费额,这个时候用余弦夹角是不恰当的,因为它会将(2,10)和(10,50)的用户算成相似用户,但显然后者的价值高得多,因为这个时候需要注重数值上的差异,而不是维度之间的差异。
两用户只对两件商品评分,向量分别为(3,3)和(5,5),显然这两个用户对两件商品的偏好是一样的,但是欧式距离给出的相似度显然没有余弦值合理。